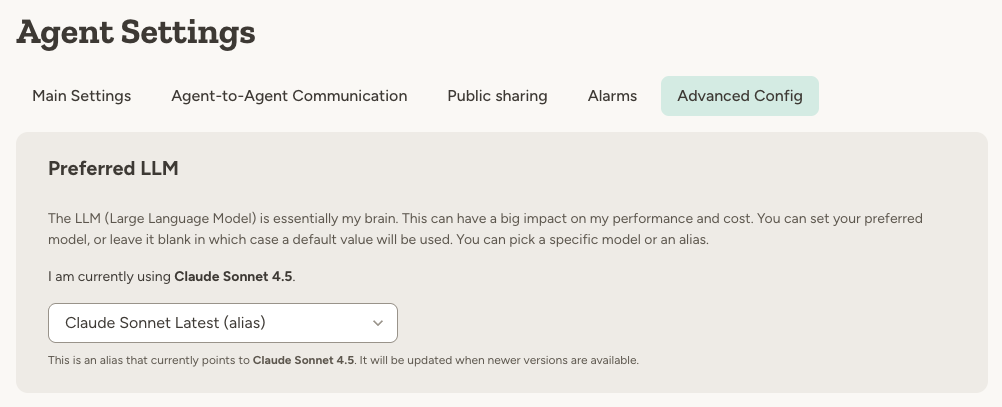
Default behavior
If you don’t have a preference, leave the model set to (no preference). This is the default, and it means Abundly will use whatever model we think works best for general agentic behavior. We continuously evaluate models and update this default as better options become available. This is the right choice for most users—you get great performance without having to think about model selection at all.Model aliases vs specific versions
When selecting a model, you can choose between:- Aliases like “Claude Sonnet Best” — automatically points to the version that we have verified works best
- Specific versions like “Claude Sonnet 4.5” — locked to that exact version
Available models
Model availability is workspace-specific. Workspace admins can turn off specific catalog models for the entire workspace from Workspace management → Model selection—useful for controlling costs or standardizing on a smaller set of models. Models that Abundly has disabled platform-wide remain locked and cannot be re-enabled at the workspace level. If an agent is configured with a model that later gets disabled, it fails fast with a clear error rather than silently substituting a different model. In chat, the disabled model appears in red with a “(disabled)” badge, and the message composer is blocked with a warning until the agent’s model is updated. On the same tab, admins can also set a workspace default model. Agents that have no model preference of their own use this model instead of the Abundly default—a quick way to standardize your whole workspace on a particular model or alias.Policy for new models
When Abundly adds a new model to the catalog, your workspace can either make it available automatically or hold it back until an admin reviews it. Choose the policy under Workspace management → Settings → LLM models:- New models on by default (the default) — New catalog models become available to your agents as soon as Abundly adds them. You can still turn any model off afterwards on the Model selection tab.
- Require approval for new models — New catalog models stay off until an admin enables them on the Model selection tab. Switching to this mode does not disable any model that is currently available; only models added to the catalog after you switch require an explicit enable.
- Anthropic Claude
- OpenAI GPT
- Google Gemini
- xAI Grok
Claude
Anthropic’s models, known for nuanced reasoning and safety
GPT
OpenAI’s models, versatile and widely capable
Gemini
Google’s models, strong at knowledge tasks and multimodal understanding
Comparing models
Not sure which model to choose? We tend to default to the Claude models (Sonnet or Opus). We find they work very well for agentic behaviour. But the other models have improved a lot lately, and some have specific strenghts that you may want to leverage. This is a changing landscape, so you’re probably best off researching online yourself (or asking an Agent to do it for you…). But here’s a high level overview of how the models from each provider compare against each other.Anthropic Claude models
Google Gemini models
OpenAI GPT models
xAI Grok models
Grok models are available when your workspace has xAI configured.
Per-context model selection
Different contexts in your agent’s life may benefit from different models. You can configure a model and thinking preference per context:- Chat — Conversations you start with the agent
- Scheduled tasks — When the agent runs on a schedule
- Email — When the agent responds to incoming emails
- Slack — When the agent responds to Slack messages
- Microsoft Teams — When the agent responds to Teams messages
- Agent messages — When other agents send your agent a message
Per-task model overrides
Individual scheduled tasks can have their own model and thinking setting on top of the per-context default. Open a task’s settings card to configure it. This is useful when one particular task needs heavier reasoning than your other scheduled tasks.Thinking mode
Many models support a thinking mode where the model spends more effort reasoning before it responds.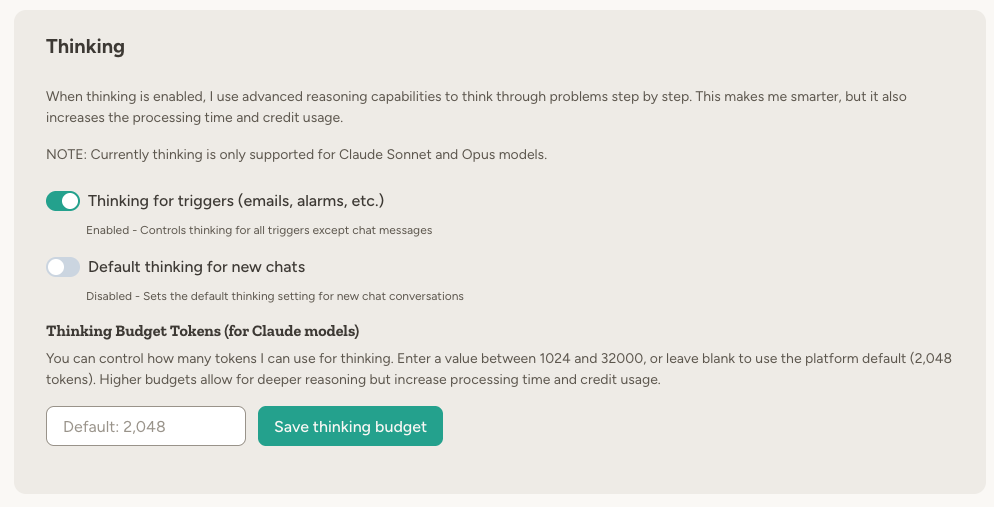
Thinking behavior depends on the selected model:
- Supports thinking — You can toggle thinking on or off
- Requires thinking — Thinking is forced on
- Does not support thinking — The thinking toggle is hidden
When to change models
Unified interface
Regardless of which model you choose, the platform provides a consistent experience:- Switch models even mid-conversation
- Same capabilities work across all models
- Consistent behavior and tool usage
- No need to learn different APIs
What if I pick a model that doesn't work well for my use case?
What if I pick a model that doesn't work well for my use case?
You can switch models at any time. If you’re not happy with the results, try a different model—your agent’s instructions and capabilities stay the same.
How does pricing work for different models?
How does pricing work for different models?
Each model has different credit costs per token. More capable models like Opus and GPT 5.2 cost more per request, while Haiku and Flash Lite are very cost-effective. Check your usage dashboard to monitor credit consumption.
Can I use different models for different agents?
Can I use different models for different agents?
Yes. Each agent can have its own model preference. You might use a fast, cheap model for a high-volume support agent and a powerful reasoning model for a research agent.
Can I use different models for different contexts within the same agent?
Can I use different models for different contexts within the same agent?
Yes. You can set a model per context (chat, scheduled tasks, email, Slack, agent messages) and even override the model on individual scheduled tasks. This lets you optimize cost and capability for each type of work the agent does.
Learn more
Anthropic (Claude)
Learn about Claude models and capabilities
OpenAI (GPT)
Learn about GPT models and capabilities
Google Gemini
Learn about Gemini models and capabilities