Security at a glance
For full details, see Infrastructure & Compliance.
Abundly Agents are autonomous by nature. If you allow them, they can make decisions and take actions on your behalf. This is very useful, but creates security considerations that go beyond traditional software. An agent with access to email and customer data could, if poorly configured, leak sensitive information. An agent stuck in a loop could consume credits rapidly. An agent with broad capabilities needs more oversight than one with narrow, read-only access. To manage this risk, the platform provides multiple layers of protection.
Multi-layer security architecture
Security is provided through multiple layers, each working together building upon each other to provide a comprehensive umbrella of protection.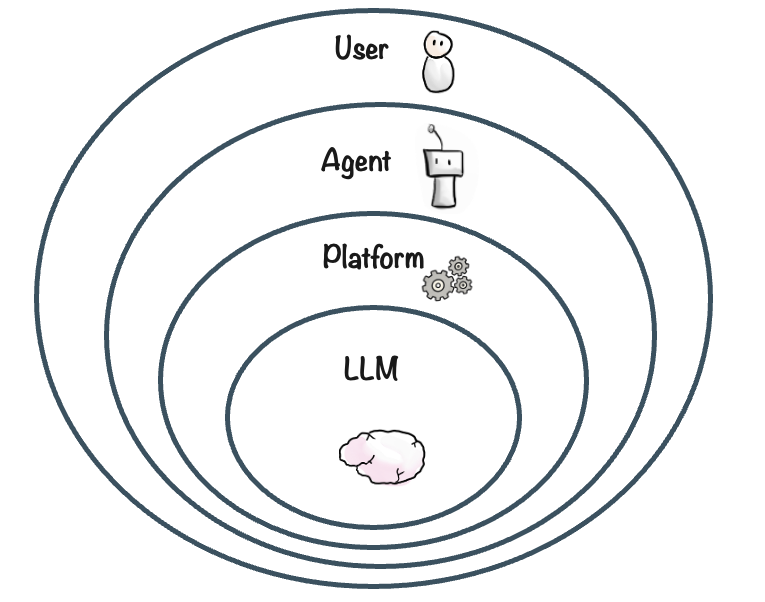
LLM layer (core)
Abundly uses Claude from Anthropic by default—an industry leader in AI safety. Claude is trained using Constitutional AI, where the model learns to follow explicit principles for helpful, honest, and harmless behavior. Before each release, Anthropic runs extensive safety evaluations including red teaming and testing with external partners like the US and UK AI Safety Institutes. Claude refuses unsafe requests, resists manipulation, and explains its reasoning when declining. You can switch to other models from OpenAI or Google—all major providers have safety measures—but Anthropic leads in this space and is our recommended default.Want to learn more about Anthropic’s safety approach? See their Responsible Scaling Policy, research publications, and trust center.
Platform layer
The Abundly platform uses the LLM as the “brain” of the agent. On top of the basic security provided by the LLM, the platform code provides a comprehensive set of additional security measures.- An internal system prompt optimized to make the LLM function as a responsible autonomous AI agent. This provides important context and guidelines that has a big impact on behavior of the agent, helping them understand their role, abilities, limitations, and risks.
- Attack detection screens untrusted trigger content (like incoming emails) for manipulation attempts before the agent acts on them.
- Guardrails enforce constraints that can’t be bypassed by prompts, for example whitelists for email addresses or phone numbers.
- Access controls limit who can do what, for example only allowing certain users to access certain agents.
Agent layer
On top of the platform, the agent itself is also a security layer. It is limited to its instructions and capabilities. An agent without email access can’t send emails, no matter what it’s asked to do.User layer (outer)
The final layer is the user - you! You decide which capabilities each agent has, configure guardrails, require approval for sensitive actions, and monitor what agents do. The platform gives you tools; you decide how to use them. A key part of the agent design process is decide the scope of the agent’s job, which tools it should have access to, and how much autonomy it should have. See Risk & Autonomy for guidance on making these decisions.Key security features
Attack Detection
Automated screening of untrusted trigger content before agent execution.
Guardrails
Technical constraints enforced by code—whitelists, limits, and restrictions that can’t be bypassed.
User Approval
Require human approval before agents execute sensitive actions like sending emails.
Access Control
Role-based permissions for users, agents, and agent-to-agent communication.
Credential Security
Encrypted storage of secrets and API keys—never exposed to the LLM.
Audit Trails
Complete logging of all agent activities for monitoring and compliance.
Usage Limits
Set daily credit limits per agent to prevent runaway costs.
Infrastructure & compliance
The platform is GDPR-compliant with all data stored in EU data centers (Stockholm). All data is encrypted at rest (AES-256) and in transit (TLS 1.2+). See Infrastructure & Compliance for details on data residency, encryption, audit trails, and certification status.FAQ
Is Abundly safe for production use?
Is Abundly safe for production use?
Yes, if you apply basic security design principles. The platform provides multiple layers of protection—from LLM training to platform guardrails to user oversight—but you need to configure them appropriately. A customer-facing agent needs more guardrails than an internal research assistant. See Risk & Autonomy for guidance.
Can agents be manipulated through prompt injection?
Can agents be manipulated through prompt injection?
Yes, but only if badly designed. An agent with broad capabilities and no guardrails could potentially be tricked into harmful actions. That’s why the platform includes multiple defenses: attack detection screens untrusted trigger content in a separate context before the agent acts on it, and guardrails are enforced by platform code rather than LLM reasoning, so they can’t be bypassed by clever prompts. The key is matching your security configuration to your risk profile—see Risk & Autonomy.